Getting Started
The math behind Gradient Descent and Backpropagation
Code example in Java using Deeplearning4J
In this article I give an introduction of two algorithms: the Gradient Descent and Backpropagation. I give an intuition on how they work but also a detailed presentation of the math behind them. At the end of this article I present an implementation of this algorithms in Java using Deeplearning4J. However, its purpose is not to introduce the Deeplearning4J framework but to implement all the concepts presented in the article. After reading this article you should have a clear understanding of why and how those two algorithms work and also be able to implement them by yourself.

Gradient Descent
There are often cases when we want to minimize a function, let’s say C. One way of doing this is to compute the derivatives and try to find the extremum point of C. If C has a small number of variables this is a viable solution, but if C has a large number of variables, as it is often the case for machine learning algorithms, this is not a practical solution anymore and we need another approach.
Let’s assume that our function looks like in Fig.1 and a random point is chosen the red point. Our goal is to reach the minimum, or the bottom, of that function. So, from our initial position, which direction shall we go to in order to reach the bottom of the valley? Intuitively, the direction is the one that points steepest down. If we go that direction a little bit, then look around and find again the direction that points steepest down and take again a little step into that direction and follow this procedure many times we’ll eventually reach the bottom of the valley. But how can we find the direction of steepest descent?

Directional derivative
To find our desired direction, the notion of directional derivative will be helpful. Let’s assume that our function C has 2 variables x and y and we want to know the instantaneous rate of change of C when moving in the direction of

The instantaneous rate of change of C along the x axis is

and similarly for y. The vector v can be thought of as v₁ units to the x direction and v₂ units to the y direction. Therefore, the directional derivative of C along the direction of vector v is

or more compactly:

where
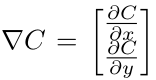
However, this is not the slope of C in the direction of v. To get the slope the norm of vector v must be 1, since v can be scaled up and that will reflect in the value of EQ(1).
Let’s come back to our initial question: if we are at the point w=(a,b), what is vector v so that it points to the steepest descent direction? Well, the instantaneous rate of change of C when moving in the direction of v has to be negative and maximum in absolute terms, it is the steepest descent. So, the problem reduces to finding:
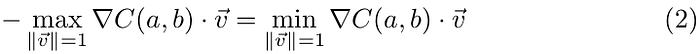
We have a dot product between two vectors, ∇ C(a,b) and v, and this is computed by multiplying the length of the projection of vector v onto ∇ C(a,b) and the length of ∇ C(a,b) (if the projection points to the opposite direction of ∇C(a, b) then its length has negative value). So, what should vector v be to minimize the product? If you swing v in all directions, it’s easy to see that the projection of v is maximum when v points to the same direction as ∇C(a, b) and the product is minimum when v points in the opposite direction of ∇C(a,b). So, the direction of steepest descent is the opposite direction of ∇C(a, b). This is the vector v we were looking for!
All left to do to approach the minimum is to update until convergence our position w as follows:

where η is called the learning rate. This is the Gradient Descent algorithm. This works not only for two variate functions but for any number of variables. To make gradient descent work correctly, η has to be carefully chosen. If η is too large the steps we take when updating w will be large and we might “miss” the minimum. On the other hand if η is too small the gradient descent algorithm will work slowly. A limitation of gradient descent algorithm is that it is susceptible to local minimum but many machine learning cost functions are convex and there’s no local minimum.
Batch gradient descent
In machine learning to measure the accuracy of a model a cost function is used. One of those functions is the Mean Squared Error or MSE:
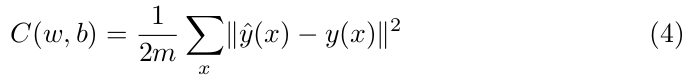
In this equation, w and b denotes the set of all weights and biases in the model, m is the number of training observations, ŷ(x) is the value outputted by the model and y(x) is the true prediction of x. C is a sum of squared terms and we want to minimize the value of it, i.e., C(w,b) ≈ 0.
To minimize the value of C(w,b) we can apply gradient descent algorithm. To do so, we can start with some initial values for w and b and then repeatedly update them until it hopefully converges to a value that minimizes C(w,b) as described above in EQ(3). However, there’s a drawback with this approach. At each iteration we have to compute the gradient ∇C. But to compute the ∇C we have to compute the gradient ∇Cₓ for each training example and then average them. When there is a large number of training observation the algorithm may be slow. To speed up things, another approach called stochastic gradient descent can be used.
Stochastic Gradient Descent
The idea of stochastic gradient descent is to use only one training observation at a time to update the parameters value. It works as follows:
- Randomly ’shuffle’ the dataset
- For i =1…m
(w, b) ← (w, b) − η · ∇C x (i) (w, b) where (w,b) is the vector containing all the values of weights and biases and
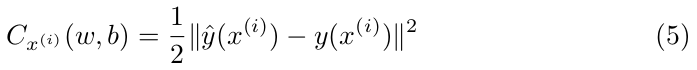
This algorithm doesn’t scan all the training observations to update the model parameters, but it tries to fit one training example at a time. Stochastic gradient descent will probably not converge at the global minimum but it can get close enough to be a good approximation.
Another approach is instead of using one training example, as in stochastic gradient descent, or all training examples, as in batch gradient descent, to use some in-between number of observation. This is called mini-batch gradient descent.
Let’s say we randomly chose k training examples, x¹, x² … xᵏ. This a mini- batch. Having a large enough mini-batch, the average value of gradients in the mini-batch will approximate the one over the entire set of training examples, that is:
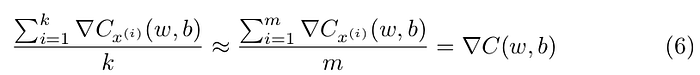
The algorithm works by randomly picking a mini-batch and updating the parameters using them:
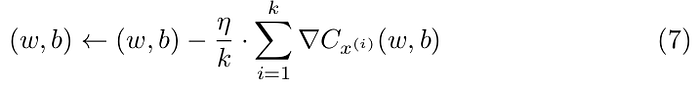
This is repeated until all the training examples are used, thus an epoch of training is completed. After that we can start with a new training epoch following the same procedure.
Neural Networks
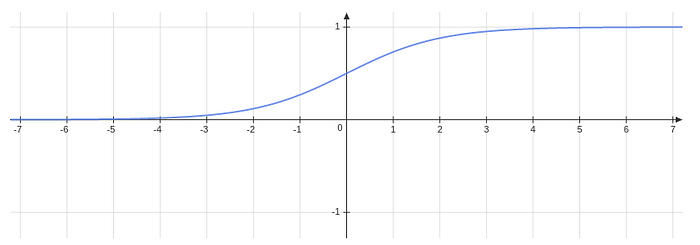
A common approach for classification problems is to use the sigmoid function.

It has weights for each input and an overall bias, b. A very nice property of this function is that σ(wᵗ · x + b) takes values in the interval (0,1), so when its output is greater than 0.5 we can classify the input as belonging to class 1 or 0 otherwise.
However, if we want to use three features including all the quadratic terms we have to compute
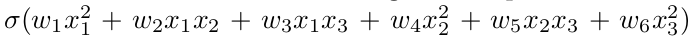
which has six features. Here we take all two-element combinations of features. More generally, to compute the number of polynomial terms we can use the combination function with repetition:
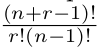
So, if our input is a 100x100 pixel black-and-white picture, the feature size will end up being (100+2–1)!/2!(100–1)=5050. Obviously, this is not practical and we need another approach.
Neural networks is another option when creating complex models with many features. The architecture of a neural network looks like following:
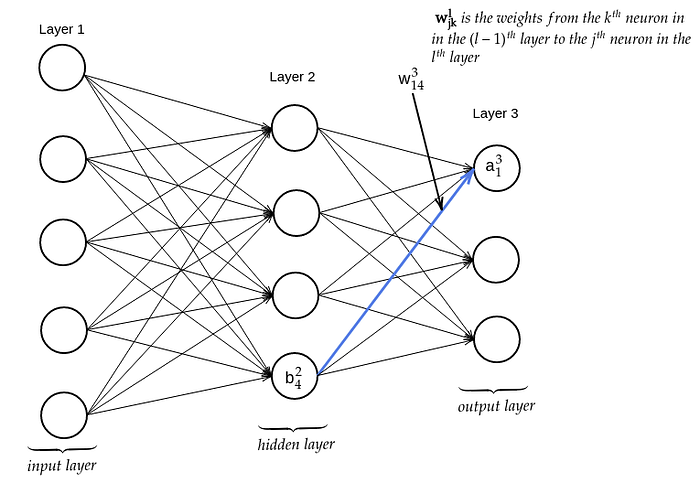
A neural network has many layers each layer having a bunch of neurons. The first layer is called the input layer and the neurons within this layer are called input neurons. The last layer is called the output layer and the neurons output neurons. The layers in the middle are called hidden layers. The output of one layer is used as the input for the next layer. These networks are called feedforward neural networks.
The sigmoid neuron works as follows. Each input x1 , x2 …xn to the neuron has a corresponding weight w1 , w2 …wn . The neuron has also an overall bias b. The output of the neuron is σ(w T · x + b) and this is the activation of the neuron. This output value will serve as input for the next layer.
The weights are denoted wˡⱼₖ meaning the weight from the kᵗʰ neuron in the layer (l-1) to the jᵗʰ neuron in the layer l. The bˡⱼ is the bias of the jᵗʰ neuron in the lᵗʰ layer. The activation of the jᵗʰ neuron in the lᵗʰ layer is aˡⱼ. For the values corresponding to the last layer superscript L is used.
For example, in a problem of classifying pictures, the input layer may consist of all pixels grayscale taking values between 0.0 and 1.0. To compute the activation value of the last neuron in layer 2 as in figure 4, we compute:
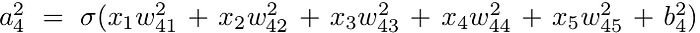
How can we train a neural network? We can use gradient descent to minimize the cost function. But to perform gradient descent we have to compute ∂C/∂w and ∂C/∂b. Next, an algorithm that computes these partial derivatives is presented.
Backpropagation
Backpropagation is the algorithm used to compute the gradient of the cost function, that is the partial derivatives ∂C/∂wˡⱼₖ and ∂C/∂bˡⱼ. To define the cost function we can use EQ(4):
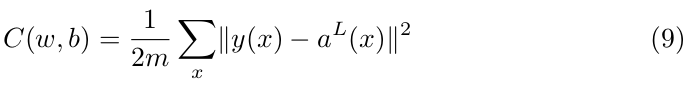
where the second term is is the vector of activation values for input x. We know that
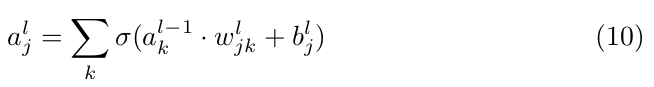
where the sum is over the k neurons in the (l − 1)ᵗʰ layer.
We can define a weight matrix Wˡ which are the weights connecting to the lᵗʰ layer and the weight wˡⱼₖ corresponds to the entry in Wˡ with row j and column k. Similarly, we can define a bias vector bˡ containing all the biases in layer l, and the vector of activations:

It is also useful to compute the intermediate value

or in the vectorized form

Obviously,

We also define the error of neuron j in layer l, as δˡⱼ . We know from gradient descent algorithm that when the partial derivative is 0 or close to zero we approached the minimum otherwise the steeper the slope the more incorrect we are. With this consideration we can define

Being equipped with all these tools we can define the error in the output layer as follows:
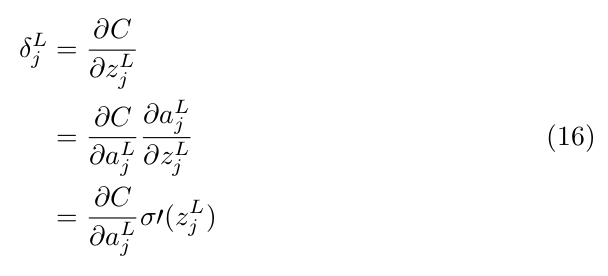
where

and if we are using the quadratic function defined in EQ (9) for one example, then
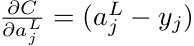
We can define ∇ₐC the vector containing partial derivatives of C with respect to each activation in the last layer then we can write the vectorized form of (16):
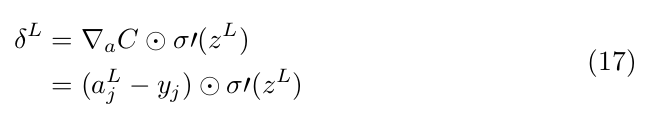
Let’s now try to compute the error of any neuron. In particular

but
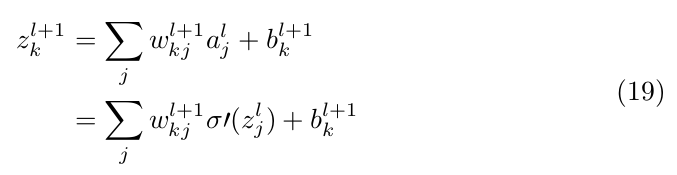
Therefore, we have

substituting in EQ(18) we get:
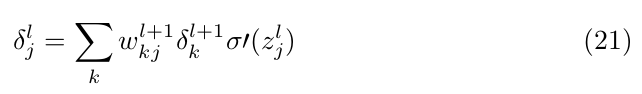
or the vectorized form:
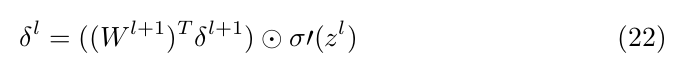
So, using this formula, if we know δ for layer l we can compute δ for l-1, l-2 etc. That is we backpropagate the error, thus the name of the algorithm. We already saw in EQ(17) how to compute δ L .
Let’s try now to compute ∂C/∂bˡⱼ
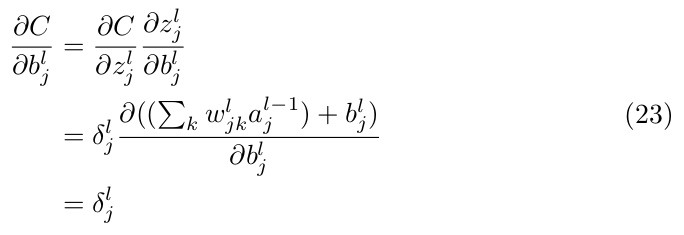
The second equality results from using EQ(15) and EQ(12). Equation (23) shows that:
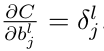
This is great news since we already saw how to compute δˡⱼ for any l. Similarly, we can compute

Equations (23) and (24) shows how to compute the gradient of the cost function.
Cross-entropy
In the previous section I described the backpropagation algorithm using the quadratic cost function (9). Another cost function used for classification problems is the Cross-entropy function.
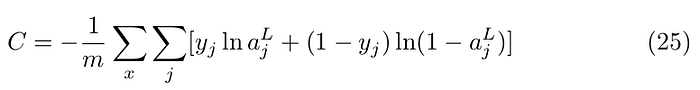
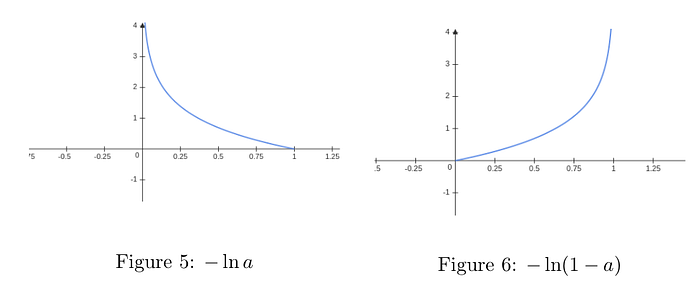
Let’s break this function into pieces and see why it makes sense. If y=1 then the second term cancels out and − ln a remains. If we look at the graph of this function we see that as a approaches 1 the value of the function approaches 0 and closer a is to 0 the function goes to infinity. That is the closer a is to the true value of y the smaller is the cost. Similarly for y=0. The remaining term is − ln(1 − a). As a approaches 1 the value of the function approaches infinity and closer a is to 0 the function goes toward zero. The sum over j in the Cross entropy function means the sum is over all neurons in the output layer.
In practice, the cross-entropy cost seems to be most often used instead of the quadratic cost function. We’ll see in a moment why that’s the case. We presented earlier the backpropagation algorithm. How does it change for this new function? Equation (16) gave us a way of computing the error in output layer and we also saw how it would look like for the quadratic cost function. Let’s now calculate it for the cross-entropy function.

It seems that the only difference with the quadratic function is that we got rid of the second term in EQ(16), the sigma prime. How important is this? If we look at Fig.3 we can notice that when the sigmoid function approaches 0 or 1 the graph is flattening, thus σ’(x) is getting very close to 0. For example if an output layer neuron will output a value very close to 0 then σ’ will be close to 0. But if the true value is 1, the value of δ being close to 0 will make the partial derivatives of the corresponding weights very small and so the learning will be very slow and many iterations will be required. But when using the cross entropy function the σ’ term disappears and the learning can be faster. The way of computing partial derivatives with respect to the weights and biases remains the same as described in the previous section, the only difference being the way of computing EQ(26).
Regularization
Regularization is a way of overcoming overfitting. There are many techniques of achieving regularization but here I’ll describe only the L2 regularization. The idea of L2 regularization is to penalize large value of weights by adding a regularization term. Then, the regularized cross-entropy becomes:
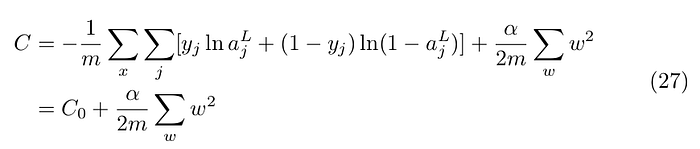
The regularization parameter is α. The biases are not included in the regularization term, so the partial derivatives with respect to the biases do not change and the gradient descent update rule doesn’t change:

The update rule for the weights becomes:
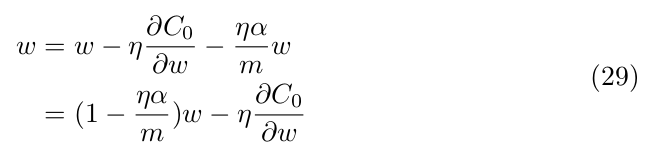
As you can notice, the first term shrinks the weight. This is also called weight decay.
Code Example
Using the notions described above we’ll try to recognize handwritten digits using the MNIST handwritten digits databse.
The full code can be found here.
First, the network is constructed specifying the layer sizes
/**
* The constructor takes as input and array of integers
* representing the number of nodes in each layer
* */
public Network(int[] layerSizes) {
this.layerSizes = Arrays.copyOf(layerSizes, layerSizes.length);
this.layers = layerSizes.length;
//initialise biases
for (int i = 1; i<layerSizes.length; i++) {
biases.add(Nd4j.randn(layerSizes[i], 1));
}
//initialise weights
for (int i = 1; i<layerSizes.length; i++) {
weights.add(Nd4j.randn(layerSizes[i], layerSizes[i-1]));
}
}To train the network, I implemented the stochastic gradient descent algorithm.
/**
* Performs mini-batch gradient descent to train the network. If test data is provided
* it will print the performance of the network at each epoch
* @param trainingData data to train the network
* @param epochs number of epochs used to train the network
* @param batchSize the size of batch
* @param eta the learning rate
* @param testData data to test the network
* */
public void SGD(DataSet trainingData, int epochs, int batchSize, double eta, DataSet testData) {
int testSize=0;
if (testData != null) {
testSize = testData.numExamples();
}
int trainingSize = trainingData.numExamples();
for (int i=0; i<epochs; i++) {
trainingData.shuffle();
for(int j=0; j<trainingSize; j+=batchSize) {
DataSet miniBatch = trainingData
.getRange(j,j+batchSize<trainingSize ? j+batchSize : trainingSize-1);
this.updateMiniBatch(miniBatch, eta);
}
if (testData != null) {
System.out.printf("Epoch %s: %d / %d ", i, this.evaluate(testData), testSize);
System.out.println();
}
}
}
/**
* Updates the weights un biases of the network using backpropagation for a single mini-batch
* @param miniBatch the mini batch used to train the network
* @param eta the learning rate
* */
public void updateMiniBatch(DataSet miniBatch, double eta) {
INDArray [] gradientBatchB = new INDArray[layers];
INDArray [] gradientBatchW = new INDArray[layers];
for (int i=0; i < this.biases.size(); i++) {
gradientBatchB[i+1] = Nd4j.zeros(this.biases.get(i).shape());
}
for (int i=0; i < this.weights.size(); i++) {
gradientBatchW[i+1] = Nd4j.zeros(this.weights.get(i).shape());
}
List<INDArray[]> result;
for(DataSet batch : miniBatch) {
result = this.backpropagation(batch.getFeatures(), batch.getLabels());
for(int i=1; i<layers; i++) {
gradientBatchB[i] = gradientBatchB[i]
.add(result.get(0)[i]);
gradientBatchW[i] = gradientBatchW[i]
.add(result.get(1)[i]);
}
}
for (int i=0; i<this.biases.size(); i++) {
INDArray b = this.biases.get(i).sub(gradientBatchB[i+1]
.mul(eta/miniBatch.numExamples()));
this.biases.set(i, b);
INDArray w = this.weights.get(i).sub(gradientBatchW[i+1]
.mul(eta/miniBatch.numExamples()));
this.weights.set(i, w);
}
}The SGD method basically takes batches from the training set and calls updateMiniBatch method. In this method the backpropagation method is called and it returns the gradient computed for that mini batch and the biases and weights arrays are updated according to the rule presented in Stochastic Gradient Descent section.
The backpropagation method computes the equations described above as follows:
//feedforward
INDArray activation = x;
INDArray [] activations = new INDArray[layers];
INDArray [] zs = new INDArray[layers];
activations[0] = x;
INDArray z;
for (int i=1; i<layers; i++) {
z = this.weights
.get(i-1).mmul(activation).add(this.biases.get(i-1));
zs[i] = z;
activation = sigmoid(z);
activations[i] = activation;
}Here are computed EQ (13) and (14) and then using (22) compute the delta terms. Having the deltas, we can compute the partial deivatives using (23)and (24). Here is the code:
//back pass
INDArray sp;
INDArray delta = costDerivative(activations[layers-1], y).mul(sigmoidPrime(zs[layers-1]));
gradientB[layers - 1] = delta;
gradientW[layers - 1] = delta.mul(activations[layers2].transpose());
for (int i=2; i<layers; i++) {
z = zs[layers-i];
sp = sigmoidPrime(z);
delta = (this.weights
.get(layers - i).transpose().mmul(delta)).mul(sp);
gradientB[layers - i] = delta;
gradientW[layers - i] = delta
.mmul(activations[layers - i - 1].transpose());
}In this article we saw how Gradient Descent and Backpropagation work. I presented the mathematical concepts that describe them and an implementation of those algorithms. You can use the code and try tuning the parameter to see how accurate your classification will be.

